[kdd cup tencent] baseline 이해하기
![[kdd cup tencent] baseline 이해하기](https://posting-files.s3.ap-northeast-2.amazonaws.com/uploads/baseline_card_v1.png)
TAAC 2026 (Tencent UNI-REC Challenge) 의 베이스라인 코드
PCVRHyFormer를 분해해본다. 코드를 그냥 돌리는 것과 "왜 이렇게 만들었나"를 이해하는 것은 다르다. 가설을 세우려면 후자가 필요하다.
1. 들어가며
대회를 시작하면서 가장 먼저 한 일은 베이스라인 코드를 받아 돌려보는 것이었다. original_code/ 폴더에 7개 파일이 있고, 메인은 model.py (65KB) 한 덩어리. 클래스 이름부터 만만치 않다.
PCVRHyFormer ├── RotaryEmbedding (RoPE) ├── SwiGLU ├── RoPEMultiheadAttention ├── CrossAttention ├── RankMixerBlock ├── MultiSeqQueryGenerator ├── SwiGLUEncoder ├── TransformerEncoder ├── LongerEncoder ├── MultiSeqHyFormerBlock ├── GroupNSTokenizer └── RankMixerNSTokenizer
처음엔 막막했다. 그래서 묻기로 했다 — 이 코드는 어떤 paper에서 왔는가? 모델명을 뜯어보니 답이 나온다.
- PCVR = Post-Click conVeRsion Rate (= 우리 태스크)
- HyFormer = Hybrid Former — 이게 base 아키텍처 이름
- RankMixer = block 이름인데 그 자체가 별도 paper
즉, 베이스라인은 HyFormer + RankMixer 두 paper의 조합이다. 이 글은 두 paper를 차례로 까고, 마지막에 우리 코드가 둘을 어떻게 합쳤는지 매핑한다.
2. 큰 문제 — sequence × feature interaction
추천 시스템에서 user가 어떤 item을 클릭/구매할지 예측하려면 두 종류의 정보가 필요하다.
| 정보 종류 | 예시 | 대표 모델 |
|---|---|---|
| Feature interaction | user 나이 × item 카테고리 = 매칭 점수 | DCN-V2, FwFM, AutoInt |
| Sequential | 최근 본 [신발A → 신발B → 신발C] → 다음 신발D? | SASRec, DIN, BERT4Rec |
문제: 두 종류 정보가 본질적으로 다르게 생겼다.
- Feature interaction은 user/item을 벡터 한 점으로 본다
- Sequential은 user를 시간순 행동 리스트로 본다
가장 흔한 통합 방식 (production):
[interaction tower] → 벡터 A [sequence tower] → 벡터 B concat([A, B]) → MLP → 예측
이걸 late fusion이라고 부른다. 두 타워가 학습 내내 서로 못 보고 마지막에 만나서 평균만 낸다. 표현력 손실.
UNI-REC의 도전은 이 둘을 같은 backbone에서 gradient를 공유하면서 통합하는 것이다. RankMixer와 HyFormer 모두 이 방향의 답안이다.
3. RankMixer (ByteDance, arXiv 2507.15551)
3.1 핵심 주장
ByteDance가 2025년 7월 발표한 paper. 한 줄 요약: "Transformer self-attention 대신 더 단순한 token mixing으로도 추천이 잘 된다, 게다가 훨씬 효율적이다".
잠깐 — token mixing이 뭔가?
추천 모델에서 입력은 보통 여러 개의 token (벡터들)이다. 예: user 정보 token 5개, item 정보 token 2개 등. 이 token들이 서로의 정보를 봐야 의미 있는 예측이 나온다.
전통적 방법은 self-attention — 각 token이 다른 모든 token에 대해 가중치를 학습해서 weighted sum을 만든다. 똑똑하지만 무겁다 (계산량 $O(T^2)$, 학습 가능한 가중치 행렬 3개 $W_Q$/$W_K$/$W_V$).
Token mixing은 같은 목표(token끼리 정보 섞기)를 훨씬 단순하게 푼다 — 학습 없이 정해진 규칙으로 token 위치를 재배치한다. 이미지 분야의 MLP-Mixer (Tolstikhin et al., NeurIPS 2021)가 self-attention 대안으로 token mixing을 처음 제안했다.
즉 token mixing 메커니즘 자체는 RankMixer가 발명한 게 아니다. RankMixer가 한 일은 다음 세 가지다:
- 추천 ranking 모델에 적용 — 이전까지 추천 분야는 transformer 일색이었다.
- 더 단순화 — MLP-Mixer는 token 축 mixing에도 학습 가능한 MLP를 썼지만, RankMixer는 학습 가중치 0개의 reshape/transpose로 줄였다.
- Industrial scale 검증 — 1B Dense-Param 모델을 production에 배포해 MFU 4.5% → 45%, A/B 테스트 lift까지 입증.
한 줄로 RankMixer의 contribution: "산업 규모 추천에서 token mixing이 transformer를 대체할 수 있음을 입증한 것". 핵심 메커니즘 자체는 MLP-Mixer 차용.
수치로 보면:
- Model FLOPS Utilization (MFU): 4.5% → 45% (10배)
- 같은 inference latency로 모델 파라미터 100배 스케일업
- 1B Dense-Param 모델 production 배포 → user active days +0.3%, in-app duration +1.08%
잠깐 — 용어 정리
- FLOPS (FLoating-point Operations Per Second): 1초당 부동소수점 연산 횟수. GPU 성능 단위로, NVIDIA A100 기준 약 312 TFLOPS (초당 312조 번 연산).
- MFU (Model FLOPS Utilization): 모델이 GPU 이론 최대 FLOPS 중 실제로 쓴 비율. 일반 추천 transformer는 4\~10% 수준 — 90% 이상은 메모리 전송·동기화로 낭비된다. RankMixer가 4.5% → 45%로 올렸다 = 같은 GPU로 약 10배 더 일을 시킬 수 있다는 뜻.
- Inference latency: 한 요청(예: "이 user에게 뭘 추천?")을 처리해 응답까지 걸리는 시간. 추천 서비스는 보통 수십\~수백 ms 안에 응답해야 함 (user를 기다리게 못 함). "같은 latency로 100배 파라미터 스케일업" = 응답 시간은 그대로인데 모델이 100배 커진다 → production에서 더 큰 모델을 굴릴 수 있게 됨.
Dense parameters (1B Dense-Param): 추천 모델 파라미터는 두 종류로 나뉜다.
- Sparse: user/item ID마다 하나씩 있는 embedding — 수십\~수백억 개지만 한 요청엔 일부만 lookup
- Dense: transformer/MLP 같은 레이어 가중치 — 모든 요청에 매번 다 계산
1B Dense = 매번 10억(1 billion)개 dense 파라미터를 다 계산하는 거대 모델. 일반 추천 모델 dense는 1\~10M 수준이니 100\~1000배 큼.
3.2 Token Mixing이 self-attention과 뭐가 다른가
잠깐 — 그래서 attention이 뭐냐?
Attention은 한마디로 "어떤 정보가 더 중요한지 가중치를 매겨서 weighted sum" 하는 메커니즘이다.
비유: 도서관에서 자료 찾기.
- Query (질문): "추천 시스템에서 cold start 문제가 뭐지?"
- Key (각 책의 색인 키워드): 책1="딥러닝", 책2="추천 cold start", 책3="그래프" ...
- Value (각 책의 내용): 책1 본문, 책2 본문, 책3 본문 ...
동작 3단계:
- 유사도 계산: query와 각 key를 내적 → score (책2가 제일 높을 것)
- softmax 정규화: score를 0\~1 가중치로 변환 (책2 ≈ 0.85, 나머지 작음)
- weighted sum: 가중치 × value → 출력 (대부분 책2 내용 + 약간의 다른 책)
수식 한 줄: $\mathrm{Attn}(Q, K, V) = \mathrm{softmax}!\left( \dfrac{Q K^\top}{\sqrt{d}} \right) V$
자주 보는 두 변형:
- Self-attention: $Q, K, V$가 같은 source에서 옴. 예: 한 문장의 단어들끼리 서로 본다.
- Cross-attention: $Q$는 한 source, $K, V$는 다른 source. 예: HyFormer에서 query token이 sequence를 본다 (§4.2에서 다룸).
즉 self/cross는 attention의 두 사용 패턴이고, 핵심 메커니즘은 같다.
Self-attention (Transformer):
$$Q = X W_Q, \quad K = X W_K, \quad V = X W_V$$
$$\ mathrm{attn} ;=; \mathrm{softmax}!\left( \frac{Q K^\top}{\sqrt{d}} \right) V$$
- 학습 가능한 가중치
W_Q,W_K,W_V필요 - 모든 token 쌍 계산 → $O(T^2 \cdot D)$ 복잡도
Token Mixing (RankMixer):
- 학습 가능한 가중치 0개. 단순 reshape + transpose.
- 복잡도 $O(T \cdot D)$ — token 개수에 선형
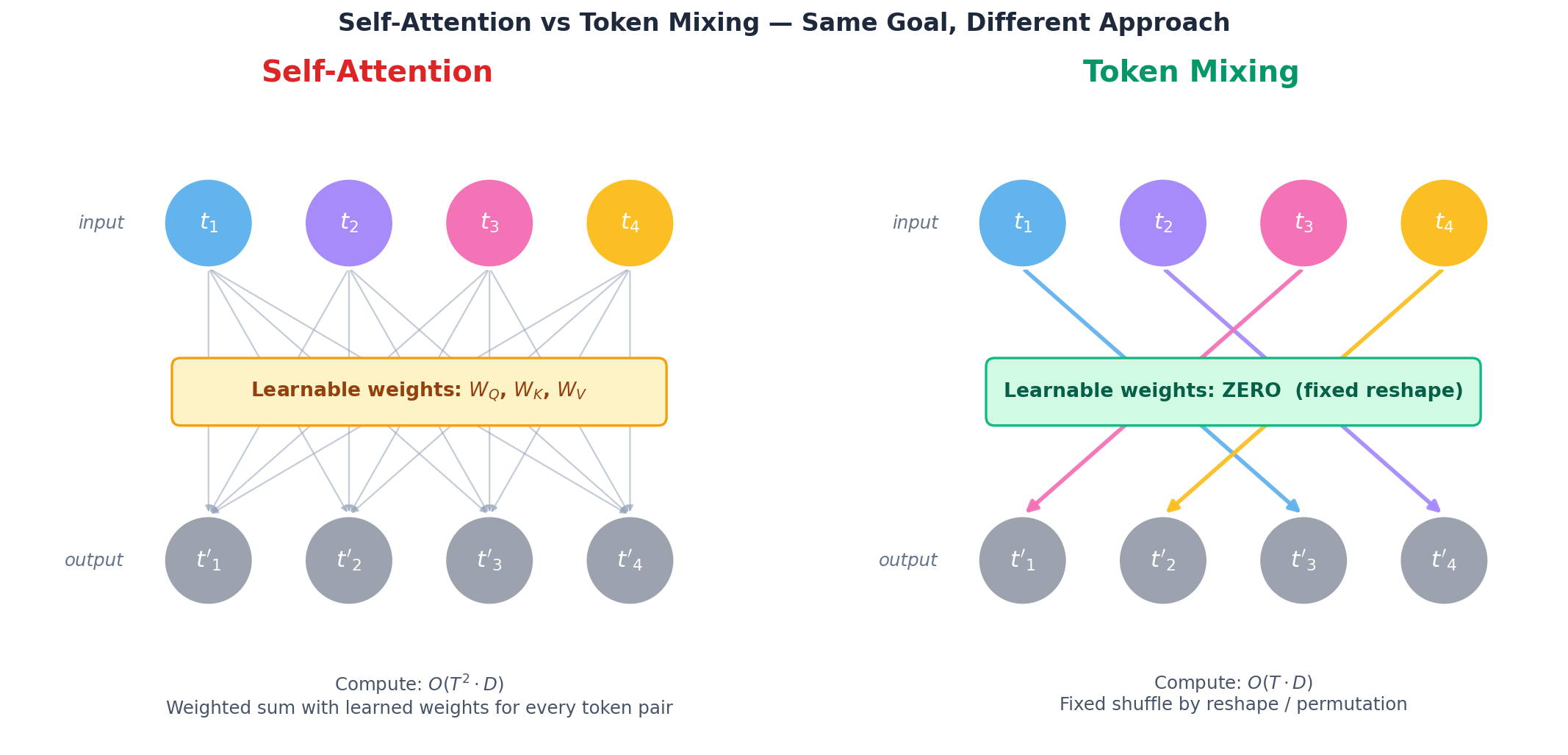
Self-Attention은 모든 토큰 쌍에 대해 학습 가중치로 weighted sum을 만들고, Token Mixing은 정해진 reshape으로 강제 섞는다 (학습 가중치 0개).
그럼 어떻게 정보를 섞는가? 코드가 가장 명확하다 (베이스라인의 RankMixerBlock.token_mixing):
def token_mixing(self, Q): """파라미터 없는 reshape으로 토큰 간 정보 mixing""" B, T, D = Q.shape # T = 토큰 수, D = 차원 # Step 1: D 차원을 T개 sub-space로 쪼갠다 # (B, T, D) -> (B, T, T, d_sub) # 각 d_sub = D / T Q_split = Q.view(B, T, self.T, self.d_sub) # Step 2: token 축과 sub-space 축을 swap # (B, token, h, d_sub) -> (B, h, token, d_sub) Q_rewired = Q_split.transpose(1, 2).contiguous() # Step 3: 다시 평평하게 # (B, T, T, d_sub) -> (B, T, D) return Q_rewired.view(B, T, D)
직관: 각 sub-space는 모든 토큰의 정보를 모은다. 그 다음 per-token FFN이 이 mixed representation을 학습 가능한 변환으로 정제. mixing 자체엔 학습이 없고 FFN만 학습한다는 게 묘미.
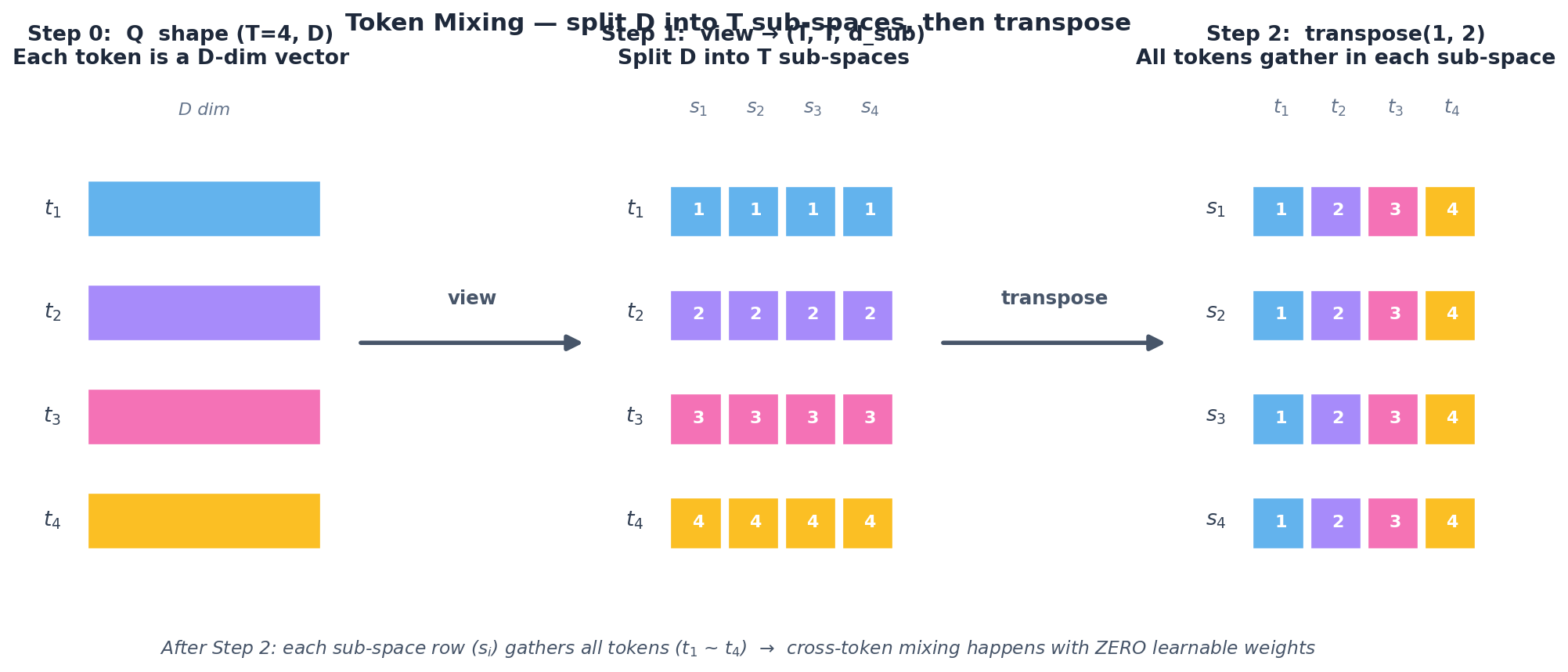
Token Mixing 3단계: D 차원을 T개 sub-space로 쪼갠 뒤 transpose하면, 각 sub-space row 안에 모든 token이 모인다 — 학습 가중치 0개로 cross-token mixing이 일어난다.
제약: $D \bmod T = 0$ 이어야 한다 (코드의
if d_model % n_total != 0: raise). 이게 베이스라인run.sh에서num_queries/num_ns값 조정해야 하는 이유다.
3.3 한 layer 흐름
잠깐 — Per-token FFN이 뭔가?
각 token에 대해 독립적으로 적용되는 작은 MLP다. token 1, 2, 3, 4 각각에 같은 가중치의 2-layer 네트워크(
Linear → activation → Linear)를 따로 적용한다. 결과적으로 token 간 정보는 섞이지 않지만, 각 token 내부의 D 차원이 비선형으로 변환된다.비유하면 각 token이 같은 헤어샵에서 같은 스타일링을 받는 것 — 머리는 안 섞이지만(token mixing이 아님), 각자 머리는 잘 정리된다. Token mixing이 "섞기" 담당, Per-token FFN이 "변환" 담당으로 역할이 분리돼 있는 게 RankMixer의 묘미.
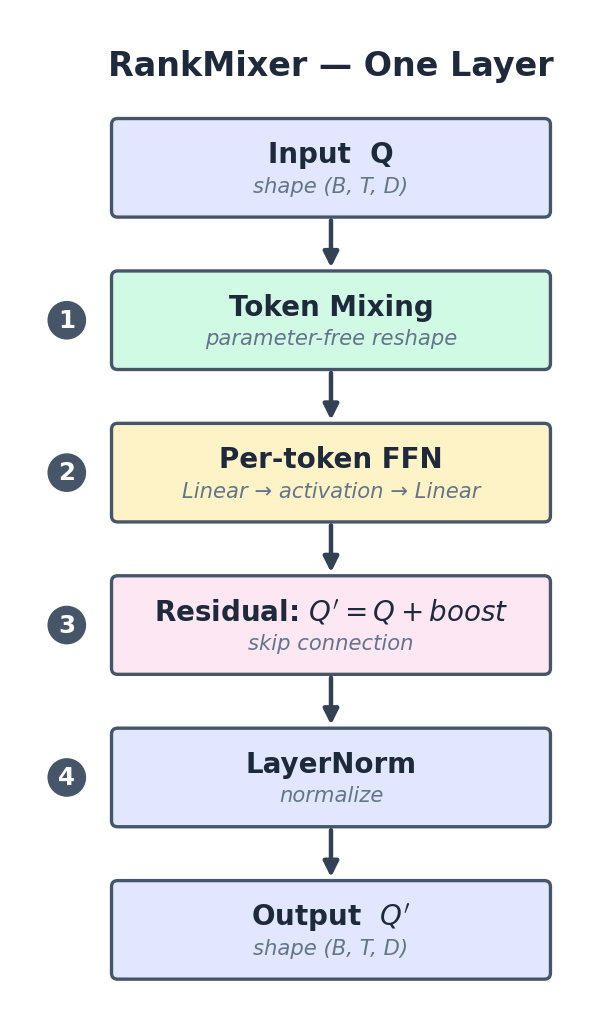
RankMixer 한 layer의 4단계 흐름. Token Mixing(섞기)과 Per-token FFN(변환)이 역할 분리돼 있고, Residual + LayerNorm으로 안정 학습.
핵심: Token mixing이 정보를 섞고 FFN이 그걸 변환. 둘이 분리돼 있어서 효율적.
4. HyFormer (arXiv 2601.12681)
4.1 핵심 주장
이게 우리 베이스라인 PCVRHyFormer의 base architecture. RankMixer의 token mixing block을 부품으로 쓰면서, 시퀀스 모델링까지 한 backbone에 통합한다.
기존 파이프라인의 한계:
긴 시퀀스 → 압축(LongerEncoder) → 짧은 벡터 → RankMixer로 feature interaction
시퀀스가 압축된 후에야 interaction이 일어난다. 시퀀스의 풍부한 정보가 손실.
잠깐 — 이 한 줄이 무슨 뜻?
추천 모델에 들어오는 데이터를 떠올려보자. user 한 명의 행동 시퀀스(예: 최근 본 영화 1000편)는 매우 길다. 이걸 통째로 transformer에 넣으면 메모리/계산이 폭발한다.
그래서 보통 2단계로 처리한다:
- 압축 단계 (
LongerEncoder): 길이 1000짜리 시퀀스를 → 짧은 벡터 한두 개로 요약 (평균 pooling, attention pooling 등).- interaction 단계 (
RankMixer): 압축된 시퀀스 벡터를 user 정적 feature(나이, 성별 등), item feature와 함께 token으로 묶어 cross interaction을 학습.문제: 1단계에서 시퀀스가 짧은 벡터로 짜부라들면, "아침에 본 영화 vs 저녁에 본 영화" 같은 시간적 디테일은 사라진다. 그 손실된 표현으로 2단계 interaction이 진행되니, 모델이 가용 정보를 다 못 쓰는 셈. → HyFormer는 이 두 단계를 분리하지 말고 layer마다 교대시켜서 시퀀스의 raw 정보가 interaction과 함께 살아있게 만든다.
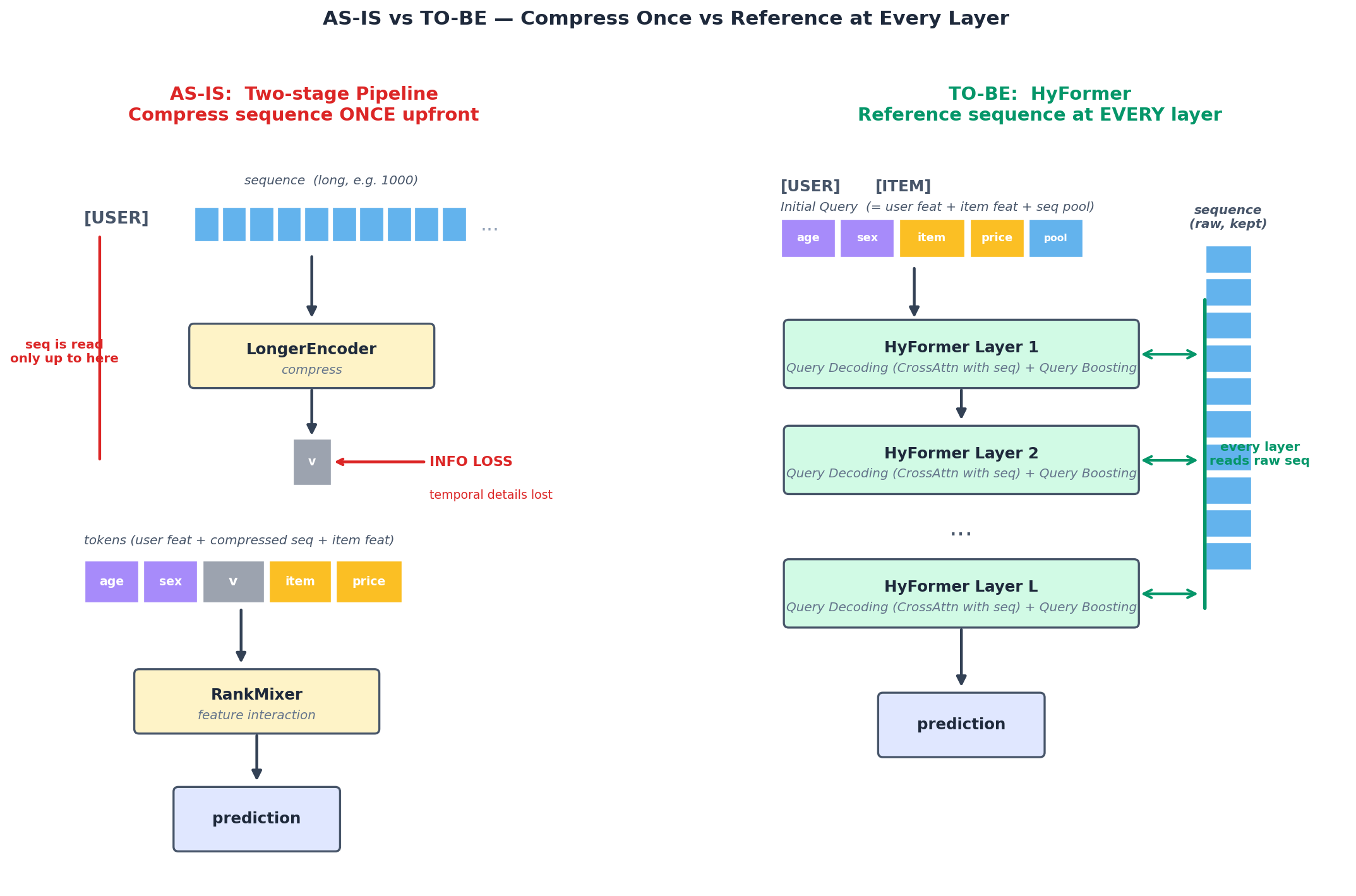
AS-IS(좌): 시퀀스를 LongerEncoder로 한 번 압축한 뒤 짧은 벡터로만 RankMixer에 들어간다 — 이때 시간적 디테일이 사라진다(INFO LOSS). TO-BE(우): HyFormer는 매 layer마다 sequence raw를 cross-attention으로 다시 참조해, 시퀀스 정보가 끝까지 살아있다.
HyFormer 답: 각 layer마다 두 step을 교대시킨다 — ① Query Decoding (token들이 sequence에서 정보를 흡수, cross-attention)과 ② Query Boosting (token끼리 서로 섞기, RankMixer 차용). 자세한 구조는 바로 다음 §4.2.
4.2 Block 구성
잠깐 — cross-attention이 뭔가?
§3.2에서 본 self-attention은 같은 token 그룹 안에서 서로 보는 것이다 — 회의실 안에서 모두가 서로 의견을 듣는 격. $Q$, $K$, $V$가 모두 같은 source에서 나온다.
Cross-attention은 두 개의 다른 token 그룹 사이에서 한쪽이 다른 쪽을 보는 것이다.
- Query ($Q$): 정보를 가져오려는 쪽 (예: HyFormer의 user/item feature token)
- Key / Value ($K$, $V$): 정보 출처 (예: user의 sequence)
비유하면 query token들이 "회의실"에 있고, sequence는 "자료실"이다. 회의실 사람들이 자료실에 가서 필요한 정보를 골라 가져오는 행위가 cross-attention이다.
HyFormer의 $Q' = \mathrm{CrossAttn}(Q, K_{\mathrm{seq}}, V_{\mathrm{seq}})$는 정확히 이런 의미 — query token $Q$가 sequence($K = V = \mathrm{seq}$)에서 정보를 가져온다.
각 HyFormer layer:
1. Query Decoding (Cross-Attention) Q' = CrossAttn(Q, K_seq, V_seq) ↓ Query 토큰들이 시퀀스에서 정보 흡수 2. Query Boosting (RankMixer Block) Q'' = RankMixerBlock(Q') ↓ Query 토큰들 사이에서 정보 mixing 3. Residual + LayerNorm
잠깐 — 시퀀스 풀링이 뭔가?
시퀀스 풀링은 여러 벡터로 된 시퀀스를 한 벡터로 요약하는 연산이다.
예시: user가 본 영화 1000편이 있고 각 영화가 $D$차원 벡터로 표현된다 → $1000 \times D$ 행렬. 이걸 $D$차원 벡터 한 개로 줄이는 게 풀링.
종류:
- Mean pooling: 모든 벡터를 평균낸다 (가장 단순, HyFormer가 사용)
- Max pooling: 차원별로 최댓값
- Attention pooling: 학습된 가중치로 weighted sum
"이 user의 영화 취향을 요약한 벡터" 같은 의미가 됨. 디테일은 사라지지만 첫 진입용 요약으론 충분 — 디테일은 나중에 cross-attention으로 다시 본다.
Query 토큰은 non-sequential feature(user 나이, item 카테고리 등)와 시퀀스 풀링 토큰의 concat:
Initial Q = Concat(F_1, F_2, ..., F_m, MeanPool(seq_a), MeanPool(seq_b), ...)
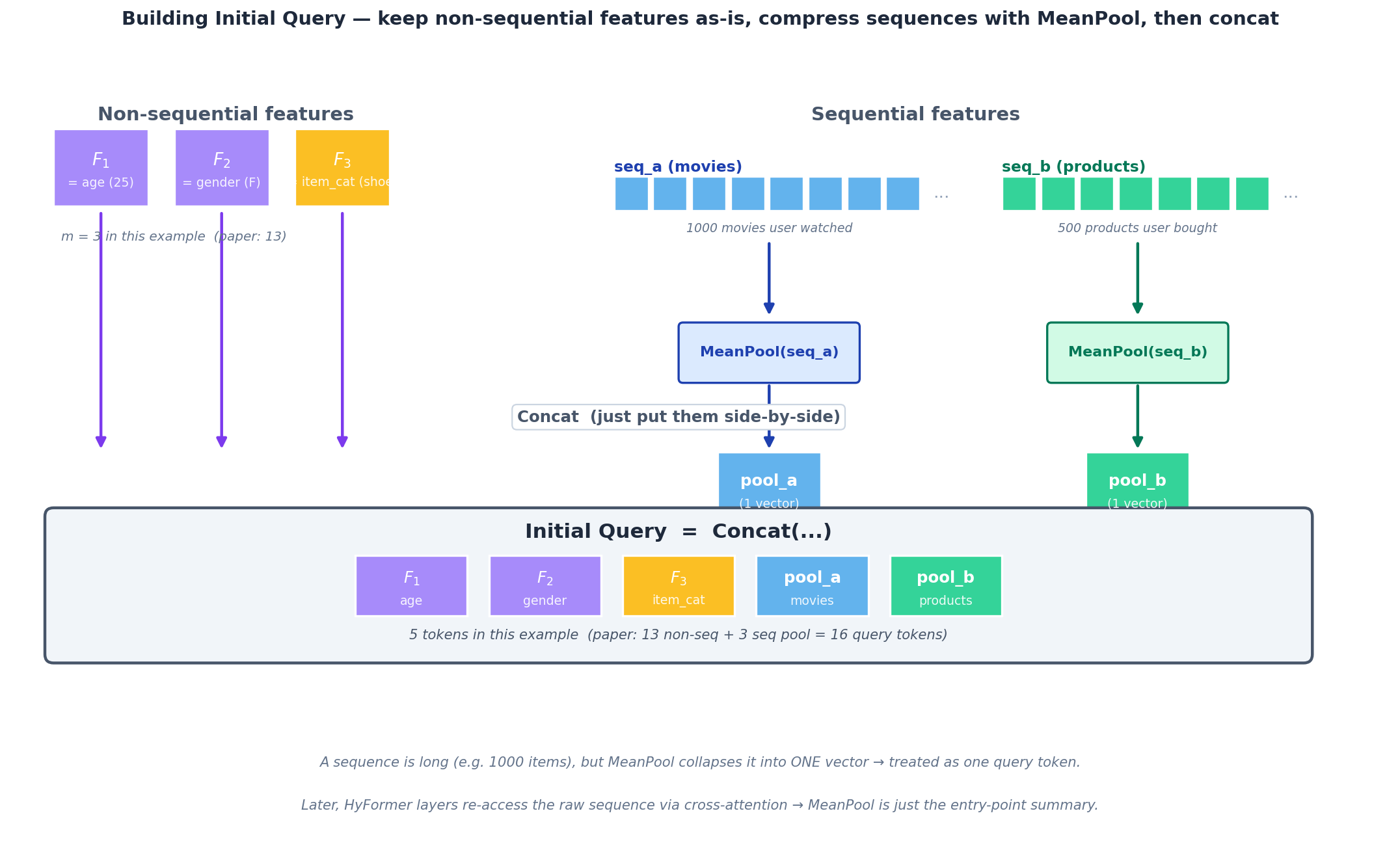
Initial Query 만들기 예시. Non-sequential features ($F_1$=age, $F_2$=gender, $F_3$=item_cat)는 그대로 token이 되고, sequential features(seq_a=영화, seq_b=상품)는 MeanPool로 한 벡터씩 압축한 뒤 모두 옆으로 concat한다. 예시는 5 token, 논문 실측은 13 + 3 = 16 token.
논문 실측: 13개 비시퀀셜 토큰 + 3개 시퀀스별 global 토큰 = 16개 query token으로 시작.
4.3 양방향 정보 흐름
시퀀스 ── Cross-Attn ──> Query 토큰 (각 layer) Query 토큰 ── RankMixer ──> Query 토큰끼리 mixing (각 layer)
층마다 두 axis가 교대로 작동 → late fusion보다 표현력 strict superset (gate를 다 닫으면 = 베이스라인).
4.4 다중 시퀀스 처리
UNI-REC 데이터는 4개 도메인 시퀀스(a/b/c/d)가 있다. HyFormer 결정: 시퀀스 병합하지 말고 각 시퀀스에 독립 query token 부여.
논문 ablation: "시퀀스 병합 시 성능 −0.06%, 독립 모델링 +0.06% → 0.12pt 차이". 의미론적 구분 보존이 중요.
5. PCVRHyFormer — 우리 베이스라인이 둘을 어떻게 합쳤나
5.1 코드 매핑
| 우리 코드 (model.py) | 출처 paper | 역할 |
|---|---|---|
RankMixerBlock |
RankMixer | Query Boosting (token mixing + per-token FFN) |
RankMixerNSTokenizer |
RankMixer | NS feature → token화 (cat all → split → project) |
MultiSeqHyFormerBlock |
HyFormer | Query Decoding + Query Boosting 교대 layer |
MultiSeqQueryGenerator |
HyFormer | 4개 도메인 시퀀스별 query token 생성 |
LongerEncoder |
HyFormer | 긴 시퀀스 1차 압축 (선택적) |
RoPEMultiheadAttention |
LLaMA | Cross-Attention의 위치 인코딩 |
SwiGLU |
LLaMA / PaLM | Per-token FFN 활성화 함수 |
CrossAttention |
HyFormer | Query Decoding 단계 |
잠깐 — 결국 feature는 어떻게 합쳐지나? (5단계)
- 모든 feature를 token으로 변환 — user int features는 embedding lookup, dense features는 projection, item features는 embedding, 4 도메인 sequence는 각각 MeanPool로 1 token씩. 결과: 약 16개 query token (각 token = D-dim 벡터).
- Query Decoding (cross-attention) — 각 token이 raw sequence를 한 번 본다.
user feature ↔ user 행동 sequence의 만남.- Query Boosting (token mixing) — token끼리 강제로 섞는다.
user feature ↔ item feature ↔ sequence poolcross.- Step 2-3을 L번 반복 — HyFormer layer를 쌓을수록 feature가 점점 더 풍부하게 합쳐짐.
- 최종 token들 → pooling → MLP → conversion 확률
핵심 정리:
- "feature를 합친다" = "모든 정보를 token으로 만들고 cross-attention + token mixing 두 메커니즘으로 서로 만나게 한다"
- Cross-attention은 token ↔ sequence (수직 cross)
- Token mixing은 token끼리 (수평 cross)
- 이 두 만남을 layer마다 반복
5.2 forward 큰 흐름
흐름을 두 단계로 분해해서 본다.
Step 1 — Tokenization: raw 4종 입력이 token으로 변환되어 Initial Query 가 만들어진다.
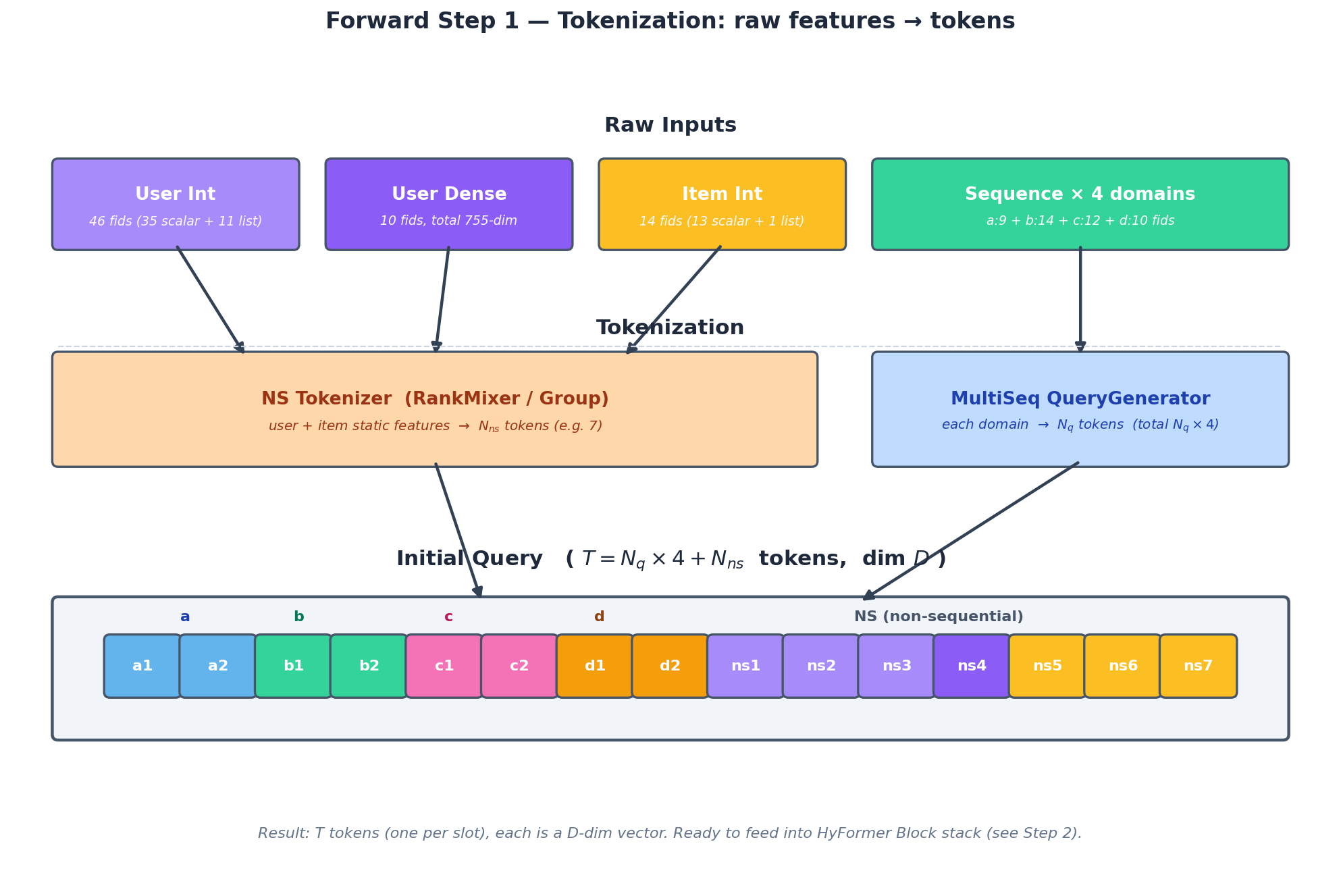
Step 1: User Int / User Dense / Item Int / 4 도메인 Sequence 가 두 종류 Tokenizer (NS Tokenizer, MultiSeq QueryGenerator)를 거쳐 $T = N_q \times 4 + N_{ns}$ 개의 token으로 만들어진다.
Step 2 — Transform & Output: Initial Query가 HyFormer Block × L를 거쳐 풍부해진 뒤 Pooling + MLP로 CVR 확률 출력.
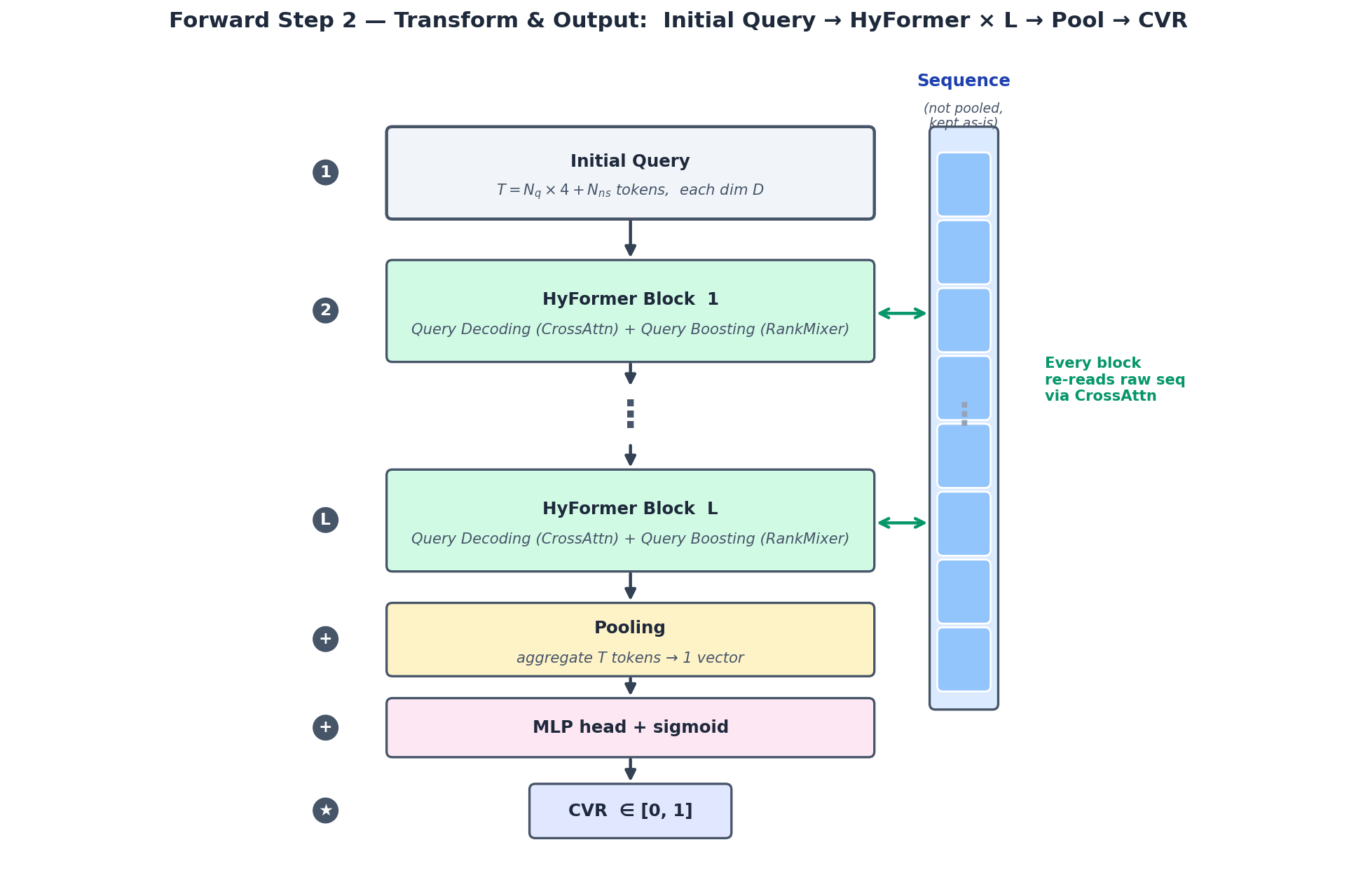
Step 2: 각 HyFormer Block 안에서 Query Decoding(cross-attention with raw sequence) + Query Boosting(RankMixer)가 매 layer 반복된다. raw sequence는 압축 안 되고 매 layer마다 다시 참조됨.
run.sh에서 active config:
--ns_tokenizer_type rankmixer # NS tokenizer는 RankMixer 방식 --user_ns_tokens 5 --item_ns_tokens 2 --num_queries 2
5.3 데이터와 매칭되는 부분
베이스라인 design choice가 데이터 특성과 어떻게 연결되는지:
- 4 도메인 시퀀스 disjoint vocab → per-domain query token (HyFormer 방식)
- p90 길이 887\~2215인 긴 시퀀스 → LongerEncoder로 1차 압축 후 cross-attn
- User dense feature가 큼 (755-dim) → NS Tokenizer가 잘게 쪼개 토큰화
6. 마무리 — 다음에 뭘 할 것인가
베이스라인을 이해하고 나니 건드릴 자리가 보인다.
- Token Mixing은 학습 안 한다 → 학습 가능한 mixing weight를 가볍게 추가하면? (rank-r low-rank projection 등)
- Query Decoding은 cross-attn 한 번만 → 두 번 또는 multi-scale로 늘리면?
- NS Tokenizer 두 가지 모드(
rankmixervsgroup) → 도메인별로 다른 토크나이저 쓰면? - OOF >> Platform 1.9\~2.6pt 일관 (cohort drift) — 동료가 9개 실험에서 못 깬 가장 큰 미해결 신호. 베이스라인 자체의 어떤 inductive bias가 OOF에 overfit 되는지 추적해볼 가치.
다음 글에선 베이스라인을 직접 학습시켜보면서 이 가설들을 하나씩 실험할 예정.
📄 참고: